文章目录[隐藏]
无锁
1. CAS
1.1 原理
无锁编程:Lock Free
CAS 的全称是 Compare-And-Swap,是 CPU 并发原语
- CAS 并发原语体现在 Java 语言中就是 sun.misc.Unsafe 类的各个方法,调用 UnSafe 类中的 CAS 方法,JVM 会实现出 CAS 汇编指令,这是一种完全依赖于硬件的功能,实现了原子操作
- CAS 是一种系统原语,原语属于操作系统范畴,是由若干条指令组成 ,用于完成某个功能的一个过程,并且原语的执行必须是连续的,执行过程中不允许被中断,所以 CAS 是一条 CPU 的原子指令,不会造成数据不一致的问题,是线程安全的
底层原理:CAS 的底层是 lock cmpxchg 指令(X86 架构),在单核和多核 CPU 下都能够保证比较交换的原子性
-
程序是在单核处理器上运行,会省略 lock 前缀,单处理器自身会维护处理器内的顺序一致性,不需要 lock 前缀的内存屏障效果
-
程序是在多核处理器上运行,会为 cmpxchg 指令加上 lock 前缀。当某个核执行到带 lock 的指令时,CPU 会执行总线锁定或缓存锁定,将修改的变量写入到主存,这个过程不会被线程的调度机制所打断,保证了多个线程对内存操作的原子性
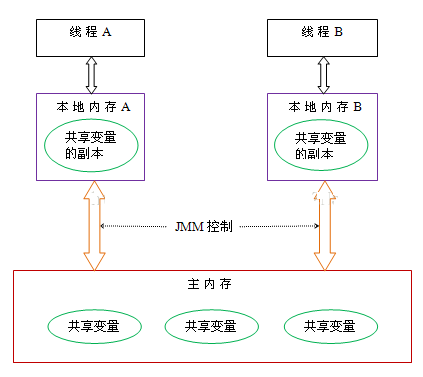
作用:比较当前工作内存中的值和主物理内存中的值,如果相同则执行规定操作,否则继续比较直到主内存和工作内存的值一致为止
CAS 特点:
- CAS 体现的是无锁并发、无阻塞并发,线程不会陷入阻塞,线程不需要频繁切换状态(上下文切换,系统调用)
- CAS 是基于乐观锁的思想
CAS 缺点:
- 执行的是循环操作,如果比较不成功一直在循环,最差的情况某个线程一直取到的值和预期值都不一样,就会无限循环导致饥饿,使用 CAS 线程数不要超过 CPU 的核心数,采用分段 CAS 和自动迁移机制
- 只能保证一个共享变量的原子操作
- 对于一个共享变量执行操作时,可以通过循环 CAS 的方式来保证原子操作
- 对于多个共享变量操作时,循环 CAS 就无法保证操作的原子性,这个时候只能用锁来保证原子性
- 引出来 ABA 问题
1.2 乐观锁
CAS 与 synchronized 对比:
- synchronized 是从悲观的角度出发:总是假设最坏的情况,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会阻塞(共享资源每次只给一个线程使用,其它线程阻塞,用完后再把资源转让给其它线程),因此 synchronized 也称之为悲观锁,ReentrantLock 也是一种悲观锁,性能较差
- CAS 是从乐观的角度出发:总是假设最好的情况,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据。如果别人修改过,则获取现在最新的值,如果别人没修改过,直接修改共享数据的值,CAS 这种机制也称之为乐观锁,综合性能较好
2. Atomic
2.1 常用API
常见原子类:AtomicInteger、AtomicBoolean、AtomicLong
构造方法:
public AtomicInteger():初始化一个默认值为 0 的原子型 Integerpublic AtomicInteger(int initialValue):初始化一个指定值的原子型 Integer
常用API:
| 方法 | 作用 |
|---|---|
| public final int get() | 获取 AtomicInteger 的值 |
| public final int getAndIncrement() | 以原子方式将当前值加 1,返回的是自增前的值 |
| public final int incrementAndGet() | 以原子方式将当前值加 1,返回的是自增后的值 |
| public final int getAndSet(int value) | 以原子方式设置为 newValue 的值,返回旧值 |
| public final int addAndGet(int data) | 以原子方式将输入的数值与实例中的值相加并返回 实例:AtomicInteger 里的 value |
2.2 原理分析
AtomicInteger 原理:自旋锁 + CAS 算法
CAS 算法:有 3 个操作数(内存值 V, 旧的预期值 A,要修改的值 B)
- 当旧的预期值 A == 内存值 V 此时可以修改,将 V 改为 B
- 当旧的预期值 A != 内存值 V 此时不能修改,并重新获取现在的最新值,重新获取的动作就是自旋
分析 getAndSet 方法:
-
AtomicInteger:
public final int getAndSet(int newValue) { /** * this: 当前对象 * valueOffset: 内存偏移量,内存地址 */ return unsafe.getAndSetInt(this, valueOffset, newValue); }valueOffset:偏移量表示该变量值相对于当前对象地址的偏移,Unsafe 就是根据内存偏移地址获取数据
valueOffset = unsafe.objectFieldOffset (AtomicInteger.class.getDeclaredField("value")); //调用本地方法 --> public native long objectFieldOffset(Field var1); -
unsafe 类:
// val1: AtomicInteger对象本身,var2: 该对象值得引用地址,var4: 需要变动的数 public final int getAndSetInt(Object var1, long var2, int var4) { int var5; do { // var5: 用 var1 和 var2 找到的内存中的真实值 var5 = this.getIntVolatile(var1, var2); } while(!this.compareAndSwapInt(var1, var2, var5, var4)); return var5; }var5:从主内存中拷贝到工作内存中的值(每次都要从主内存拿到最新的值到本地内存),然后执行
compareAndSwapInt()再和主内存的值进行比较,假设方法返回 false,那么就一直执行 while 方法,直到期望的值和真实值一样,修改数据 -
变量 value 用 volatile 修饰,保证了多线程之间的内存可见性,避免线程从工作缓存中获取失效的变量
private volatile int valueCAS 必须借助 volatile 才能读取到共享变量的最新值来实现比较并交换的效果
分析 getAndUpdate 方法:
-
getAndUpdate:
public final int getAndUpdate(IntUnaryOperator updateFunction) { int prev, next; do { prev = get(); //当前值,cas的期望值 next = updateFunction.applyAsInt(prev);//期望值更新到该值 } while (!compareAndSet(prev, next));//自旋 return prev; }函数式接口:可以自定义操作逻辑
AtomicInteger a = new AtomicInteger(); a.getAndUpdate(i -> i + 10); -
compareAndSet:
public final boolean compareAndSet(int expect, int update) { /** * this: 当前对象 * valueOffset: 内存偏移量,内存地址 * expect: 期望的值 * update: 更新的值 */ return unsafe.compareAndSwapInt(this, valueOffset, expect, update); }
2.3 原子引用
原子引用:对 Object 进行原子操作,提供一种读和写都是原子性的对象引用变量
原子引用类:AtomicReference、AtomicStampedReference、AtomicMarkableReference
AtomicReference 类:
-
构造方法:
AtomicReference<T> atomicReference = new AtomicReference<T>() -
常用 API:
public final boolean compareAndSet(V expectedValue, V newValue):CAS 操作public final void set(V newValue):将值设置为 newValuepublic final V get():返回当前值
public class AtomicReferenceDemo {
public static void main(String[] args) {
Student s1 = new Student(33, "z3");
// 创建原子引用包装类
AtomicReference<Student> atomicReference = new AtomicReference<>();
// 设置主内存共享变量为s1
atomicReference.set(s1);
// 比较并交换,如果现在主物理内存的值为 z3,那么交换成 l4
while (true) {
Student s2 = new Student(44, "l4");
if (atomicReference.compareAndSet(s1, s2)) {
break;
}
}
System.out.println(atomicReference.get());
}
}
class Student {
private int id;
private String name;
//。。。。
}2.4 原子数组
原子数组类:AtomicIntegerArray、AtomicLongArray、AtomicReferenceArray
AtomicIntegerArray 类方法:
/**
* i the index
* expect the expected value
* update the new value
*/
public final boolean compareAndSet(int i, int expect, int update) {
return compareAndSetRaw(checkedByteOffset(i), expect, update);
}2.5 原子更新器
原子更新器类:AtomicReferenceFieldUpdater、AtomicIntegerFieldUpdater、AtomicLongFieldUpdater
利用字段更新器,可以针对对象的某个域(Field)进行原子操作,只能配合 volatile 修饰的字段使用,否则会出现异常 IllegalArgumentException: Must be volatile type
常用 API:
static <U> AtomicIntegerFieldUpdater<U> newUpdater(Class<U> c, String fieldName):构造方法abstract boolean compareAndSet(T obj, int expect, int update):CAS
public class UpdateDemo {
private volatile int field;
public static void main(String[] args) {
AtomicIntegerFieldUpdater fieldUpdater = AtomicIntegerFieldUpdater
.newUpdater(UpdateDemo.class, "field");
UpdateDemo updateDemo = new UpdateDemo();
fieldUpdater.compareAndSet(updateDemo, 0, 10);
System.out.println(updateDemo.field);//10
}
}2.6 原子累加器
原子累加器类:LongAdder、DoubleAdder、LongAccumulator、DoubleAccumulator
LongAdder 和 LongAccumulator 区别:
相同点:
- LongAddr 与 LongAccumulator 类都是使用非阻塞算法 CAS 实现的
- LongAddr 类是 LongAccumulator 类的一个特例,只是 LongAccumulator 提供了更强大的功能,可以自定义累加规则,当accumulatorFunction 为 null 时就等价于 LongAddr
不同点:
- 调用 casBase 时,LongAccumulator 使用 function.applyAsLong(b = base, x) 来计算,LongAddr 使用 casBase(b = base, b + x)
-
LongAccumulator 类功能更加强大,构造方法参数中
- accumulatorFunction 是一个双目运算器接口,可以指定累加规则,比如累加或者相乘,其根据输入的两个参数返回一个计算值,LongAdder 内置累加规则
- identity 则是 LongAccumulator 累加器的初始值,LongAccumulator 可以为累加器提供非0的初始值,而 LongAdder 只能提供默认的 0
3. LongAdder
3.1 优化机制
LongAdder 是 Java8 提供的类,跟 AtomicLong 有相同的效果,但对 CAS 机制进行了优化,尝试使用分段 CAS 以及自动分段迁移的方式来大幅度提升多线程高并发执行 CAS 操作的性能
CAS 底层实现是在一个循环中不断地尝试修改目标值,直到修改成功。如果竞争不激烈修改成功率很高,否则失败率很高,失败后这些重复的原子性操作会耗费性能(导致大量线程空循环,自旋转)
优化核心思想:数据分离,将 AtomicLong 的单点的更新压力分担到各个节点,空间换时间,在低并发的时候直接更新,可以保障和 AtomicLong 的性能基本一致,而在高并发的时候通过分散减少竞争,提高了性能
分段 CAS 机制:
- 在发生竞争时,创建 Cell 数组用于将不同线程的操作离散(通过 hash 等算法映射)到不同的节点上
- 设置多个累加单元(会根据需要扩容,最大为 CPU 核数),Therad-0 累加 Cell[0],而 Thread-1 累加 Cell[1] 等,最后将结果汇总
- 在累加时操作的不同的 Cell 变量,因此减少了 CAS 重试失败,从而提高性能
自动分段迁移机制:某个 Cell 的 value 执行 CAS 失败,就会自动寻找另一个 Cell 分段内的 value 值进行 CAS 操作
3.2 伪共享
Cell 为累加单元:数组访问索引是通过 Thread 里的 threadLocalRandomProbe 域取模实现的,这个域是 ThreadLocalRandom 更新的
// Striped64.Cell
@sun.misc.Contended static final class Cell {
volatile long value;
Cell(long x) { value = x; }
// 用 cas 方式进行累加, prev 表示旧值, next 表示新值
final boolean cas(long prev, long next) {
return UNSAFE.compareAndSwapLong(this, valueOffset, prev, next);
}
// 省略不重要代码
}Cell 是数组形式,在内存中是连续存储的,64 位系统中,一个 Cell 为 24 字节(16 字节的对象头和 8 字节的 value),每一个 cache line 为 64 字节,因此缓存行可以存下 2 个的 Cell 对象,当 Core-0 要修改 Cell[0]、Core-1 要修改 Cell[1],无论谁修改成功都会导致当前缓存行失效,从而导致对方的数据失效,需要重新去主存获取,影响效率
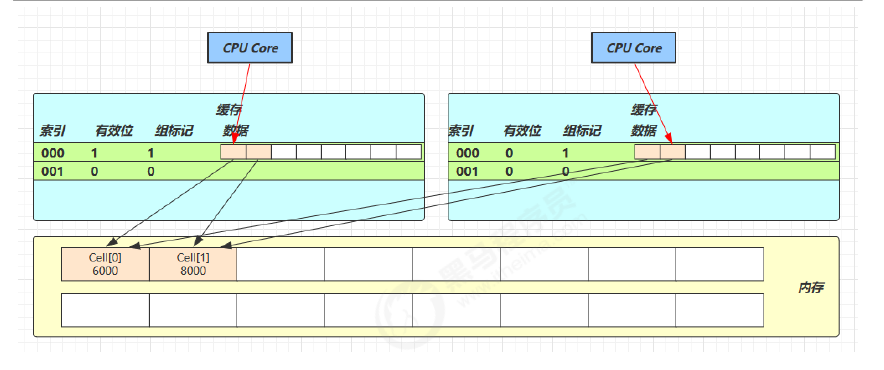
@sun.misc.Contended:防止缓存行伪共享,在使用此注解的对象或字段的前后各增加 128 字节大小的 padding,使用 2 倍于大多数硬件缓存行让 CPU 将对象预读至缓存时占用不同的缓存行,这样就不会造成对方缓存行的失效

4. ABA
ABA 问题:当进行获取主内存值时,该内存值在写入主内存时已经被修改了 N 次,但是最终又改成原来的值
其他线程先把 A 改成 B 又改回 A,主线程仅能判断出共享变量的值与最初值 A 是否相同,不能感知到这种从 A 改为 B 又 改回 A 的情况,这时 CAS 虽然成功,但是过程存在问题
-
构造方法:
public AtomicStampedReference(V initialRef, int initialStamp):初始值和初始版本号
-
常用API:
public boolean compareAndSet(V expectedReference, V newReference, int expectedStamp, int newStamp):期望引用和期望版本号都一致才进行 CAS 修改数据public void set(V newReference, int newStamp):设置值和版本号public V getReference():返回引用的值public int getStamp():返回当前版本号
public static void main(String[] args) {
AtomicStampedReference<Integer> atomicReference = new AtomicStampedReference<>(100,1);
int startStamp = atomicReference.getStamp();
new Thread(() ->{
int stamp = atomicReference.getStamp();
atomicReference.compareAndSet(100, 101, stamp, stamp + 1);
stamp = atomicReference.getStamp();
atomicReference.compareAndSet(101, 100, stamp, stamp + 1);
},"t1").start();
new Thread(() ->{
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
if (!atomicReference.compareAndSet(100, 200, startStamp, startStamp + 1)) {
System.out.println(atomicReference.getReference());//100
System.out.println(Thread.currentThread().getName() + "线程修改失败");
}
},"t2").start();
}5. Unsafe
Unsafe 是 CAS 的核心类,由于 Java 无法直接访问底层系统,需要通过本地(Native)方法来访问
Unsafe 类存在 sun.misc 包,其中所有方法都是 native 修饰的,都是直接调用操作系统底层资源执行相应的任务,基于该类可以直接操作特定的内存数据,其内部方法操作类似 C 的指针
模拟实现原子整数:
public static void main(String[] args) {
MyAtomicInteger atomicInteger = new MyAtomicInteger(10);
if (atomicInteger.compareAndSwap(20)) {
System.out.println(atomicInteger.getValue());
}
}
class MyAtomicInteger {
private static final Unsafe UNSAFE;
private static final long VALUE_OFFSET;
private volatile int value;
static {
try {
//Unsafe unsafe = Unsafe.getUnsafe()这样会报错,需要反射获取
Field theUnsafe = Unsafe.class.getDeclaredField("theUnsafe");
theUnsafe.setAccessible(true);
UNSAFE = (Unsafe) theUnsafe.get(null);
// 获取 value 属性的内存地址,value 属性指向该地址,直接设置该地址的值可以修改 value 的值
VALUE_OFFSET = UNSAFE.objectFieldOffset(
MyAtomicInteger.class.getDeclaredField("value"));
} catch (NoSuchFieldException | IllegalAccessException e) {
e.printStackTrace();
throw new RuntimeException();
}
}
public MyAtomicInteger(int value) {
this.value = value;
}
public int getValue() {
return value;
}
public boolean compareAndSwap(int update) {
while (true) {
int prev = this.value;
int next = update;
// 当前对象 内存偏移量 期望值 更新值
if (UNSAFE.compareAndSwapInt(this, VALUE_OFFSET, prev, update)) {
System.out.println("CAS成功");
return true;
}
}
}
}